
2026 年 3 月 31 日,Claude Code 2.1.88 的 npm 发布包意外包含了 sourcemap。事件公开后,外界据此还原出近 1,900 个 TypeScript 文件、约 51.2 万行客户端代码。Anthropic 随后确认,这是一次由人工发布流程导致的打包问题,没有暴露用户数据或凭据。
这批代码是 Claude Code 客户端,不是 Claude 模型,也不是 Anthropic 的服务端推理系统。它展示的是终端交互、Agent 编排、工具执行、权限控制、上下文管理、记忆、压缩和 MCP 接入等工程实现,但这恰恰是最值得研究的部分。
大模型决定能力的理论上限,客户端 Harness 决定这些能力能否被稳定、安全、低成本地交付给用户。读完这套实现后,我最强烈的感受不是“Claude 的 Prompt 有多神奇”,而是:
一个生产级 Agent,本质上是一套围绕概率模型构建的运行时系统。
先看Claude Code全貌
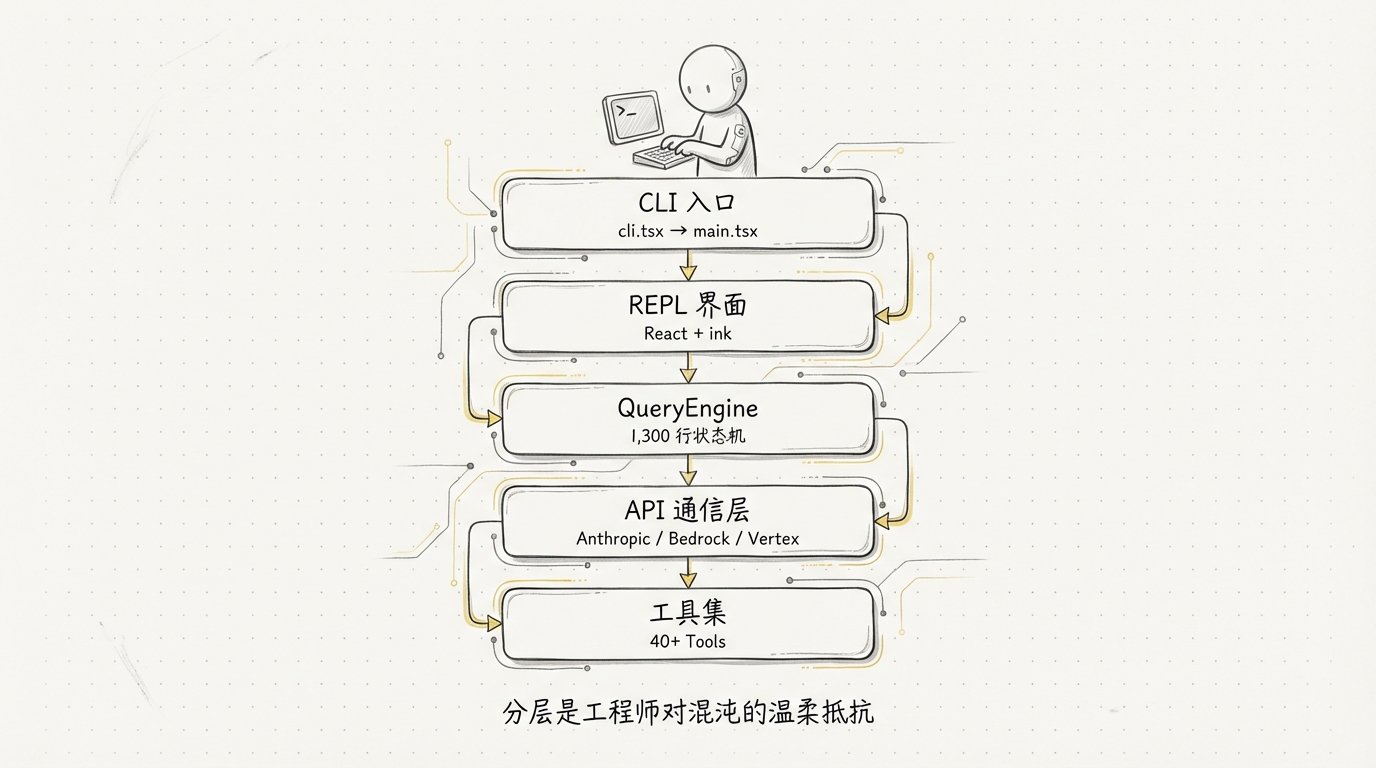
可以把它拆成六层:
- CLI 与终端 UI 层:解析参数、接收输入、流式渲染结果。
- 会话管理层:维护消息历史、配置、会话生命周期和压缩状态。
- Agent Loop 层:调用模型、解析工具请求、执行动作并决定是否继续。
- 工具与权限层:让模型读写文件、执行命令、访问网络,同时限制危险行为。
- 上下文与记忆层:把项目规则、Git 状态、会话历史和长期记忆组织成模型可用的信息。
- API 客户端层:处理流式请求、重试、模型选择、Prompt Cache 和多后端适配。
一次普通请求,会经历如下旅程:
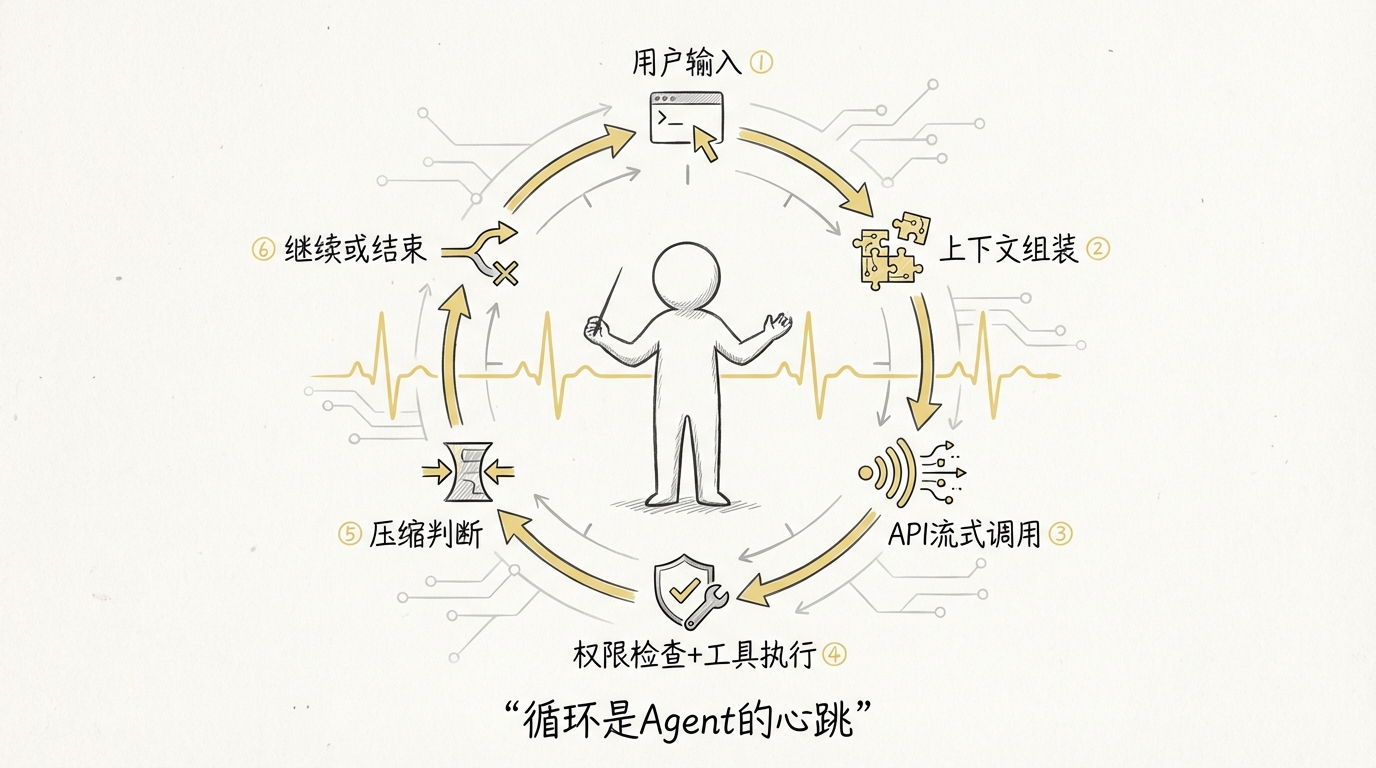
用户输入先被区分为自然语言、Slash Command 或直接 Shell 命令。自然语言进入 Agent Loop 后,系统加载项目指令和环境信息,组装上下文并调用模型。模型如果返回工具调用,客户端先做权限检查,再执行工具,把结果追加回消息历史,随后再次调用模型。这个过程一直循环,直到模型结束任务,或达到轮次、Token、权限等边界。
这与普通聊天产品有一个根本区别:聊天产品的核心动作是“生成文本”,Coding Agent 的核心动作是“在不确定环境中持续推进任务”。
Agent Loop
大语言模型本身并不会主动读文件,也不会在命令失败后自动重试。它接收输入、生成输出,然后结束。所谓 Agent,是模型外部的程序不断重复下面这个过程:
|
|
Claude Code 的核心循环采用 AsyncGenerator 组织。这个选择很适合终端 Agent:模型输出可以逐段 yield 给 UI;遇到权限确认时可以暂停;工具返回后又可以从原位置继续。
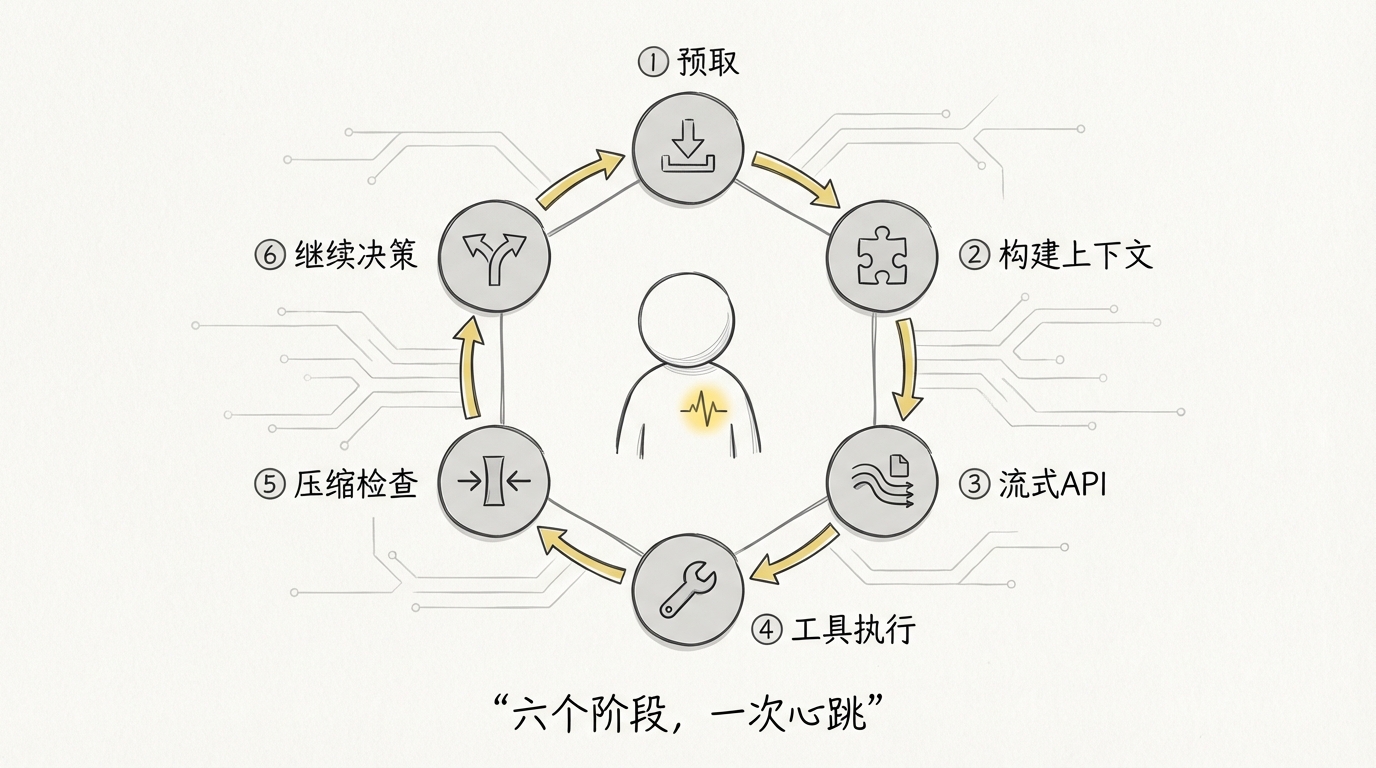
从还原样本看,一轮循环大致分为六个阶段:
- 预取:并行加载项目指令、可用 Skill、Git 状态等 I/O 信息。变化不频繁的内容会在会话内缓存,避免几十轮循环重复读取。
- 构建上下文:组合核心指令、项目上下文、历史消息、工具定义和当前权限状态。上下文不是静态字符串,而是每轮都会重新评估的输入结构。
- 流式调用模型:模型生成的文本实时显示在终端;如果模型选择行动,则返回结构化的
tool_use请求,而不是让客户端从自然语言里猜命令。 - 执行工具:工具调用依次经过参数校验、Hook、权限判断、工具查找、执行与结果清洗。相互独立的读取和搜索可以并行执行,单个工具失败也不必拖垮整轮任务。
- 检查上下文容量:工具输出往往比用户对话更占空间。系统需要估算 Token 使用量,在接近上下文上限前清理旧结果或生成摘要。
- 决定继续还是结束:如果模型仍要调用工具,就开始下一轮;如果返回结束信号,就把最终答案交给用户。
这套循环真正解决的不是“如何调用一次 API”,而是四个更难的问题:
- 如何让每一步都有实时反馈;
- 如何在几十轮执行中保持状态一致;
- 如何让失败可恢复,而不是直接终止;
- 如何让子任务拥有独立上下文,又不污染主任务。
Claude Code 会为部分 Skill、压缩任务和子任务创建独立 Agent。隔离后的子 Agent 有自己的消息历史、Token 预算和工具范围,完成后只把结果返回主会话。这已经很接近操作系统的进程模型:主循环负责调度,子 Agent 负责隔离执行。
Context Engineering
模型的能力不只取决于参数,也取决于它在当前时刻看到了什么。
一个 Coding Agent 的上下文里同时竞争空间的内容包括:
- 核心行为指令;
- 用户需求与历史对话;
- 项目规则和个人偏好;
- Git 分支、变更与最近提交;
- 工具定义;
- 文件内容、搜索结果和命令输出;
- 长期记忆与当前任务进度。
把所有信息一股脑塞给模型并不是好策略。上下文越长,成本越高,Prompt Cache 越容易失效,关键信息也越可能被噪声淹没。
Claude Code 的做法可以概括为三个词:分层、按需、稳定前缀。
分层:先保护不能丢的信息
项目规则、权限边界和用户原始意图的优先级最高;最近对话次之;体积大、时效性差的旧工具输出最先被清理。这样即使长任务经历多次压缩,Agent 仍然知道“要做什么”和“不能做什么”。
按需:只加载当前真正需要的内容
Claude Code 支持通过 CLAUDE.md、.claude/rules/ 和导入机制组织项目指令,也支持自动记忆。当前公开版本会为项目维护独立的记忆目录,启动时只加载 MEMORY.md 的前 200 行或前 25KB,更详细的主题笔记按需读取。
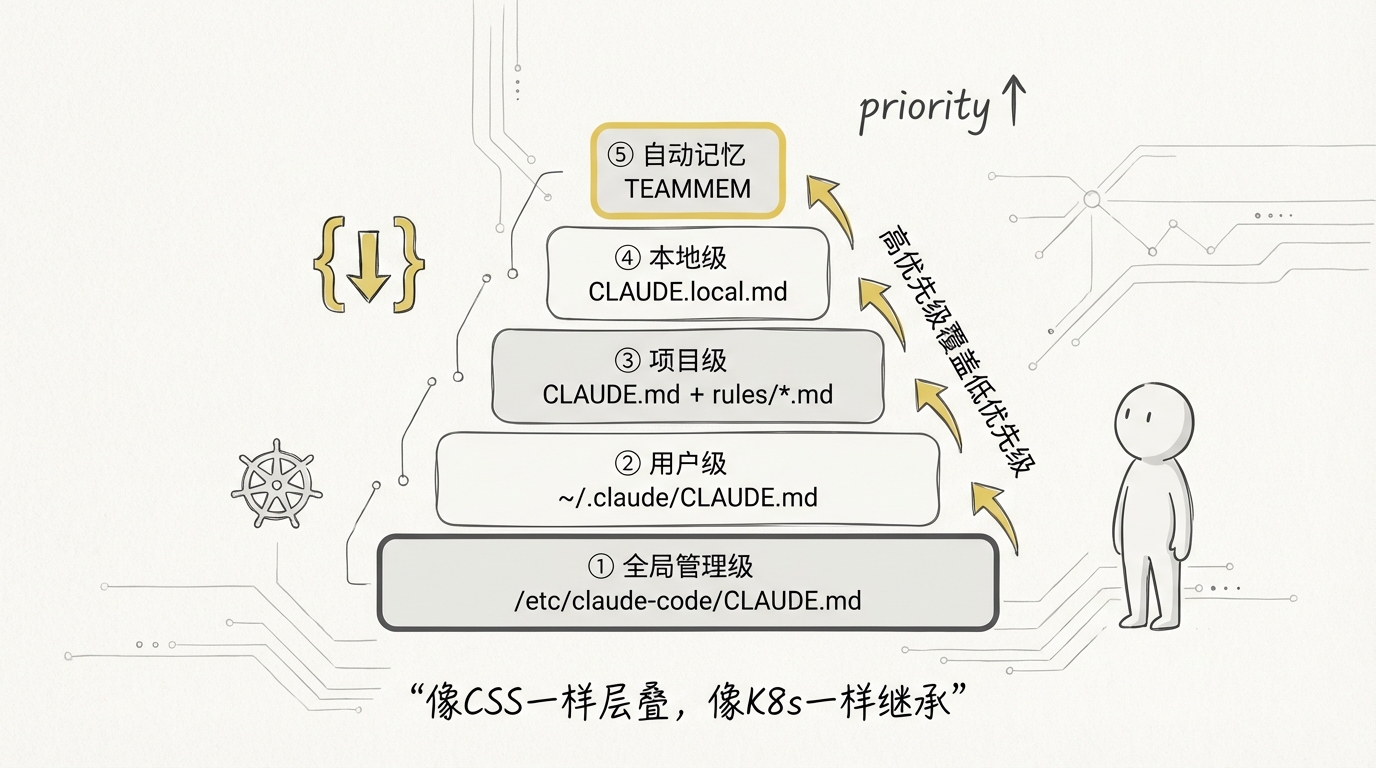
这里最重要的不是文件名,而是设计思想:
- 指令记忆回答“这个项目应该怎么做”;
- 长期记忆回答“过去有哪些经验值得下次继续使用”;
- 会话状态回答“当前任务已经做到哪里”。
把三者混在一起,记忆会迅速变成垃圾场;把生命周期分开,Agent 才能长期使用。
稳定前缀:让 Prompt Cache 真正命中
模型每一轮都需要重新接收历史上下文。如果请求前缀保持一致,API 可以复用缓存,只处理新增内容。反过来,工具描述、MCP 列表或项目上下文中的动态文本一旦频繁变化,就会让后续内容全部失去缓存。
因此,Context Engineering 不只是让模型回答更准,也直接关系到延迟和成本。一个生产级 Agent 必须同时管理信息价值、注意力预算和缓存结构。
三层压缩
Agent 对上下文的消耗远快于普通聊天。读一个大文件、跑一次测试、抓一段日志,都可能产生数千 Token。复杂任务运行几十轮后,再大的窗口也会被填满。
Claude Code 没有等到溢出后粗暴截断,而是采用渐进式压缩。
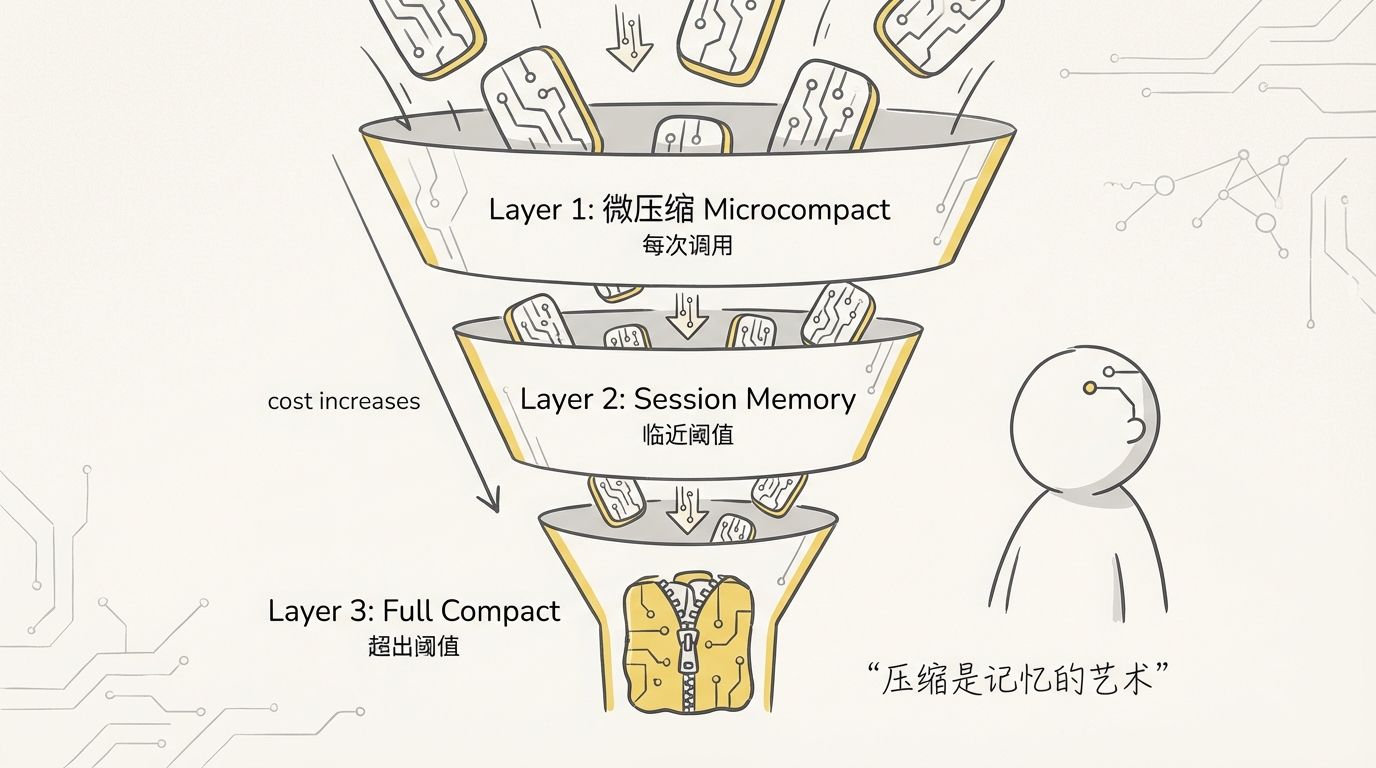
Layer1: Microcompact
旧的文件读取、搜索结果和命令输出体积很大,而且可能已经被后续修改覆盖。系统优先清理这类低价值内容,保留用户消息、关键回复与近期结果。
Layer2: Session Memory
把重要决策、已修改文件、错误原因和待办事项提取成更紧凑的状态,再删除已被记录的原始消息。这类似于程序员在调试过程中写工作日志。
Layer3: Full Compact
当局部清理仍不够时,独立的压缩 Agent 会把历史整理成结构化摘要,保留用户目标、关键技术信息、文件变更、错误与修复、当前进度和下一步。
这里有两个值得复用的技巧。
第一,摘要不只回答之前发生了什么,还要回答现在正在做什么和下一步是什么。只做回顾性摘要,Agent 压缩后很容易失去任务方向。
第二,让模型先分析、再输出正式摘要,最终只保留摘要。中间分析可以提升质量,却不必继续占用主上下文。
更重要的是,压缩流程本身也必须被当成生产系统来治理:需要失败上限、递归保护、状态重置和可观测性。还原样本中的事故注释显示,自动压缩曾因缺少熔断机制反复失败并持续重试。最终的修复原则很朴素:
任何无人值守的自动流程,都必须有预算、超时和熔断器。
Tool, Skill , MCP
如果 Agent Loop 是调度器,工具就是系统调用。
Claude Code 把文件读取、精确编辑、完整写入、内容搜索、文件匹配、Shell、Web、Notebook、子 Agent 等能力拆成独立工具。
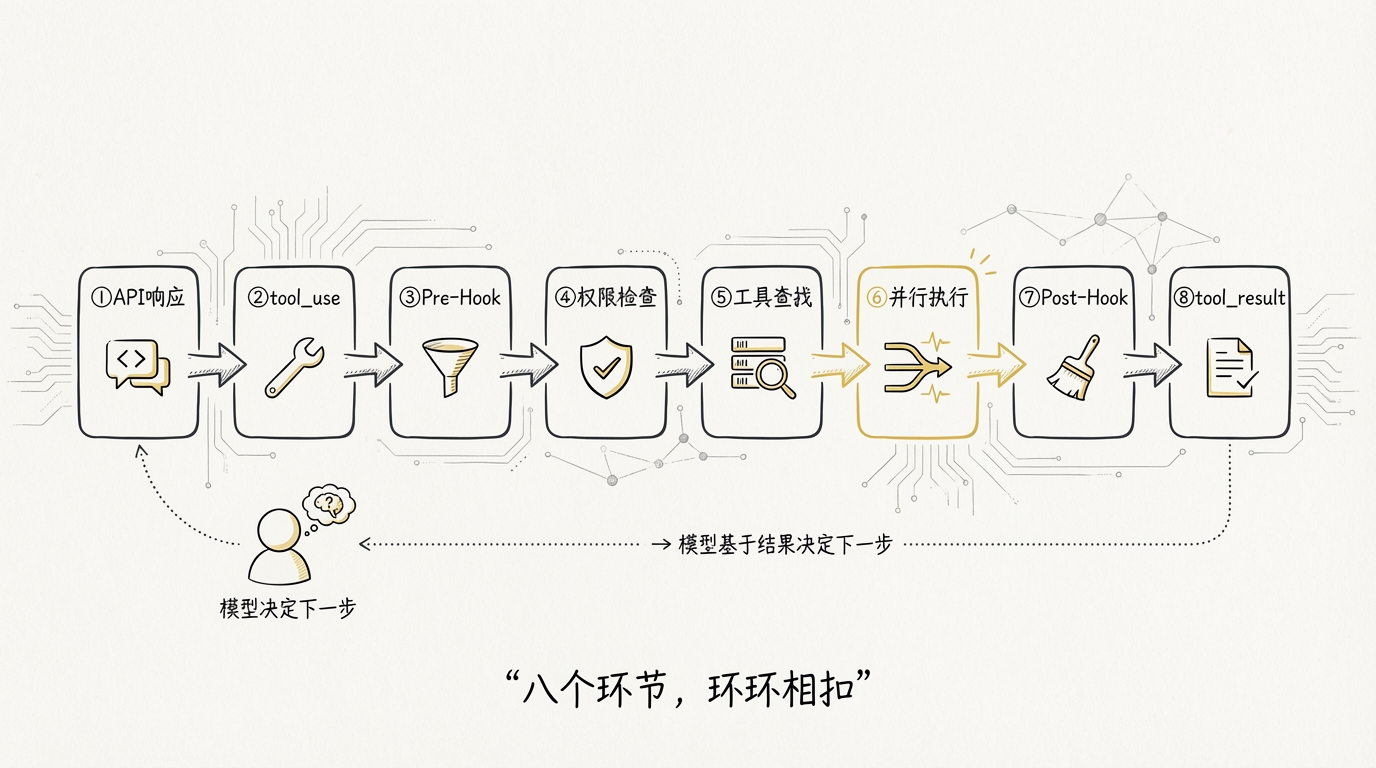
一条成熟的工具流水线至少包含:
|
|
Skill
Skill 的入口是 SKILL.md。它不是传统意义上的二进制插件,而是一份可包含脚本、模板和示例的任务说明。系统先把 Skill 的名称和描述提供给模型,只有确认需要时才加载完整内容,避免所有 Skill 同时挤占上下文。
Skill 还可以选择在独立上下文中运行,并限定可用工具。这种设计兼顾了低门槛、按需加载和执行隔离。
MCP
MCP 解决的是生态接入问题。没有协议时,GitHub、Slack、数据库和浏览器都要分别适配;有了 MCP,Agent 可以通过统一接口发现和调用外部工具。
需要区分内部实现与公开产品接口:还原样本中可以看到多种配置来源和传输适配分支;当前公开文档面向用户提供 local、project、user 三种主要作用域,并支持企业托管配置,常用传输方式包括本地 stdio、远程 HTTP 和仍在兼容的 SSE。
MCP 真正困难的地方不是发送一段 JSON,而是连接生命周期、认证、超时重试、动态工具发现、配置合并和第三方服务隔离。协议代码越接近生产,边界条件往往越多。
权限与沙箱
传统程序的执行路径由代码决定;Agent 的路径由模型在运行时选择。再加上文件、网页和 MCP 返回内容都可能携带 Prompt Injection,安全控制不能只靠静态 Code Review,必须发生在每次行动之前。
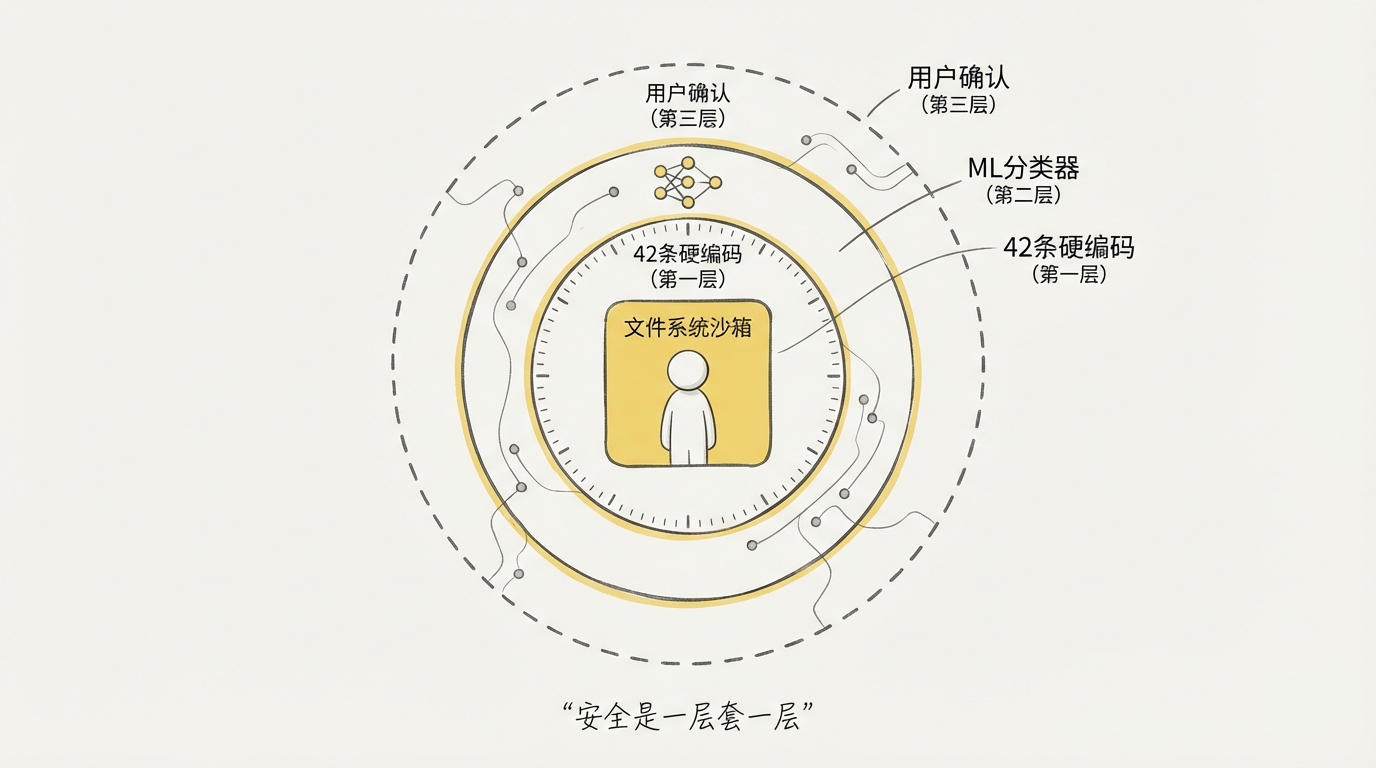
Claude Code 的安全体系可以概括为四层。
1. 权限模式
还原样本重点展现了 default、auto 和 plan 等路径。当前公开文档中的模式已经扩展为:
default:读取可直接执行,修改和命令通常需要确认;acceptEdits:自动接受工作区内的文件修改和部分常见文件操作;plan:以探索和规划为主,不修改源码;auto:通过后台分类器评估工具调用;dontAsk:只允许预先批准的动作,其余直接拒绝;bypassPermissions:跳过大多数权限检查,只应在隔离环境中使用。
这说明权限不是一个简单的开关,而是“监督强度”的连续谱。
2. 规则与分类器
样本中存在一组针对解释器、Shell 包装器和高风险命令模式的默认分类规则。它们不应被理解成在所有模式下都绝对不可绕过的静态黑名单;实际结果还受权限模式、用户规则、受保护路径和显式绕过配置影响。
硬编码规则负责已知风险,模型分类器负责语义风险。两者结合,比只用正则或只相信另一个模型更稳妥。
3. 受保护路径与权限规则
.git、.claude、Shell 配置和 MCP 配置等路径需要更严格的写入控制。用户和团队还可以配置 allow、ask、deny 规则,把安全策略固化到项目配置中。
4. 操作系统级沙箱
真正可靠的边界不能只靠模型自觉。Claude Code 的 Bash 沙箱使用操作系统能力限制文件系统和网络访问:工作区内可写,其他路径和新网络域名按规则拦截或请求批准。权限系统决定“能不能调用工具”,沙箱决定“命令运行后实际上能碰到什么”,两者互补。
Feature Flag 展示的不是承诺,而是探索空间
还原样本中有大量 Feature Flag,涉及自主运行、多 Agent 协调、上下文管理、自动验证、工作流脚本、语音和远程触发等方向。

如果只看方向,可以归纳出四个明显趋势:
- 更长时间的自主运行:Agent 从“一问一答”走向围绕目标持续工作。
- 多 Agent 协作:主 Agent 负责拆解、调度、汇总和验证。
- 上下文生命周期管理:从单次有损摘要走向快照、分支和按需恢复。
- 确定性工作流回归:对发布、审计等高风险任务,用固定步骤约束模型的随机性。
这也解释了为什么 Harness Engineering 会长期存在。模型越强,Agent 能做的事情越多,调度、安全、成本和可观测性反而越重要。
从源码事件重新理解 AI Coding 的 Code Review
这次事件最直接的教训,不是“AI 写的代码不可靠”。目前没有足够证据仅凭代码风格判断这些代码由谁编写。Anthropic 对外确认的是发布打包流程出现了人工错误,Claude Code 负责人也提到本应进一步自动化的手工发布步骤。
真正值得关注的是:一个系统即使类型检查通过、功能完善、错误处理充分,也可能在构建与发布阶段因为一个遗漏暴露整个客户端源码。
还原样本中,一个入口文件超过 5,000 行、依赖树包含数百个包。这些现象值得做架构和供应链审查,但同样不能直接证明代码由 AI 生成。更稳妥的结论是:随着功能增长,复杂度会集中到入口模块和第三方依赖中,团队需要主动设置文件规模、依赖准入和模块边界。
因此,AI Coding 时代的 Review 重心需要上移。
人的价值正在从亲手敲出每一行代码,转向定义约束、验证结果、设计系统并对后果负责。